Abstract
We introduce InternVLA-M1, a unified framework for spatial grounding and robot control that advances instruction-following robots toward general-purpose intelligence. Its core idea is spatially guided vision-language-action training, where spatial grounding serves as the critical link between instructions and robot actions. InternVLA-M1 employs a two-stage pipeline: (i) spatial grounding pre-training on over 2.3M spatial reasoning data to determine “where to act” by aligning instructions with visual, embodiment-agnostic positions, and (ii) spatially guided action post-training to decide “how to act” by generating embodiment-aware actions through plug-and-play spatial prompting. This spatially guided training recepit yields consistent gains: InternVLA-M1 outperforms its variant without spatial guidance by +13.6% on SimplerEnv Google Robot, +17% on WidowX, and +4.3% on LIBERO Franka. To further scale instruction following, we built a simulation engine to collect 244K pick-and-place episodes, enabling a 6.2% average improvement across 200 tasks and 3K+ objects. In real-world clustered pick-and-place, InternVLA-M1 improved by 7.3%, and with synthetic co-training, achieved +20.6% on unseen objects and novel configurations. Moreover, in long-horizon reasoning-intensive scenarios, it surpassed existing works by over 10 points. These results highlight spatially guided training as a unifying principle for scalable and resilient generalist robots.
Model Overview
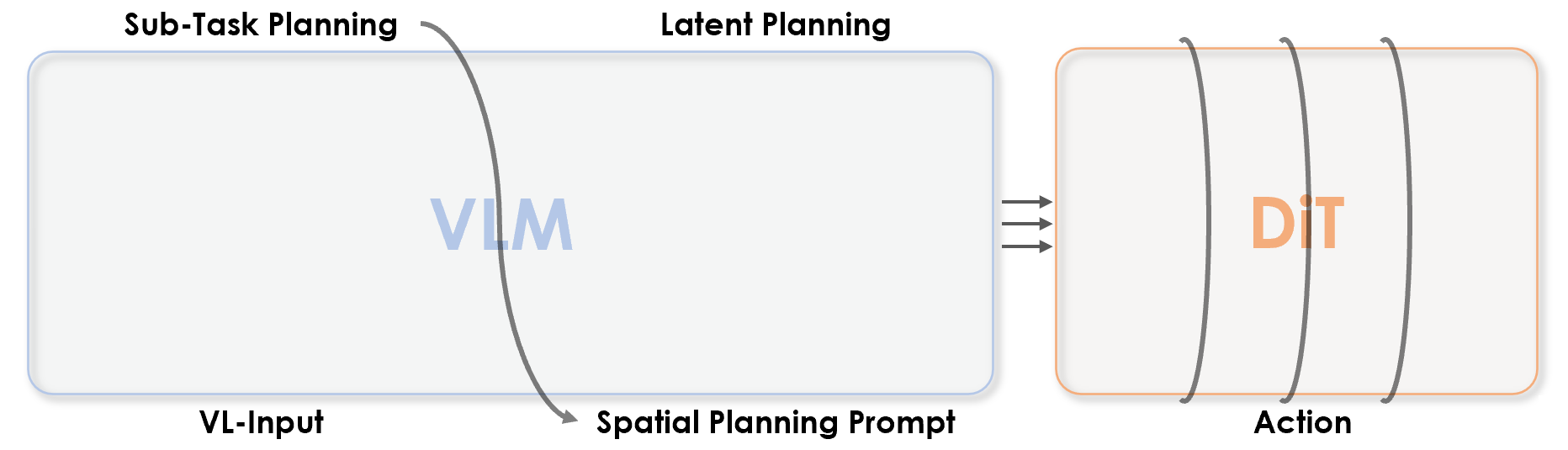
InternVLA-M1 integrates spatial grounding into the vision–language–action training pipeline. Given a task instruction, the VLM planner produces latent plans through explicit spatial prompting, which then effectively guides the action expert to generate control signals.
Simulation Data Generation

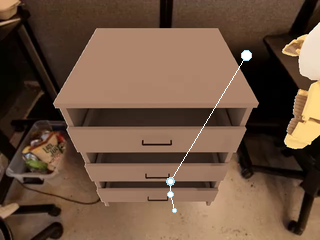
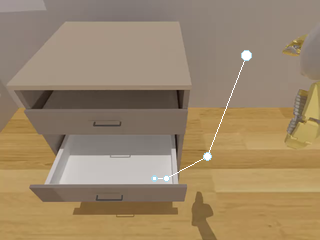
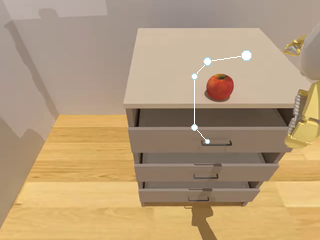
The pipeline automatically generates diverse instruction-following robotic manipulation data from a large asset library, incorporating intermediate representations such as Box, Point, and Trajectory, which can be further converted into VLM spatial grounding data.
Results
Watch InternVLA-M1 perform instruction-following manipulation tasks in both large-scale simulated environments and real-world tasks.